Early Ranking
Luminide includes an optimization, called Early Ranking, which uses predictive modeling to determine the relative outcome of a training run after only a few epochs. This can be used for rapid prototyping, e.g. experimenting with different model layers or data transformations, as well as for more effective hyperparameter tuning, since exploring larger search spaces can lead to higher accuracy models.
Experimental Phase
Early ranking is still in the experimental phase. In many cases it has achieved the same results using 5 to 10 times fewer epochs, but in some cases the accuracy or speedup falls short of this goal. We encourage you to try it out and let us know how well it works for you. One thing you can do is the following:
Train your model (i.e. full training).
Perform hyperparameter tuning using Early Ranking (i.e. fast sweep).
Train your model again (i.e. full training) using the best result from your hyperparameter sweep. You can do this by copying the contents of config-tuned.yaml (accessed with Menu:
Experiment Tracking > Output) into config.yaml. Or by logging into the IDE server and running something like this: ubuntu@ide-server:~/plant-pathology$ cp output/exp47/config-tuned.yaml code/config.yaml
Ideally this will produce a higher accuracy model in a fraction of the time. Optionally, repeat steps 2 and 3 a few times with different values of epochs in the fast.sh script, and create an accuracy/speedup curve. Sharing your results will help us characterize and improve our Early Ranking technology (send email to support@luminide.com).
Fast Training
Early Ranking can be used by data scientists to do rapid prototyping. Simply check the Fast Training box when executing a single training run.
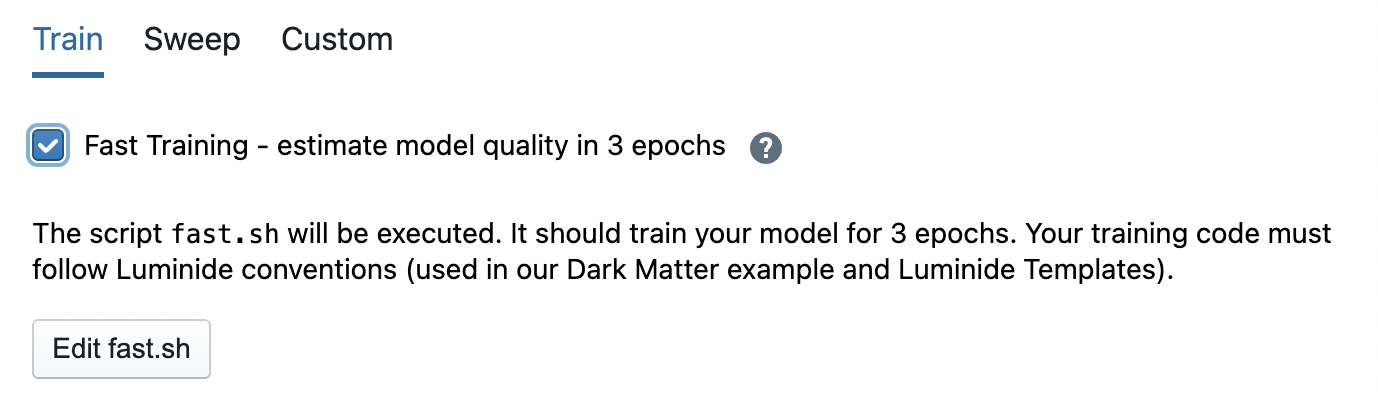
Fast Sweeps
Early Ranking can also be used for Hyperparameter Tuning. Similarly, check the Fast Sweep box to enable this feature. Each of the trials in the fast sweep will then execute a fewer number of epochs, and then use the predictive model to compute its score.
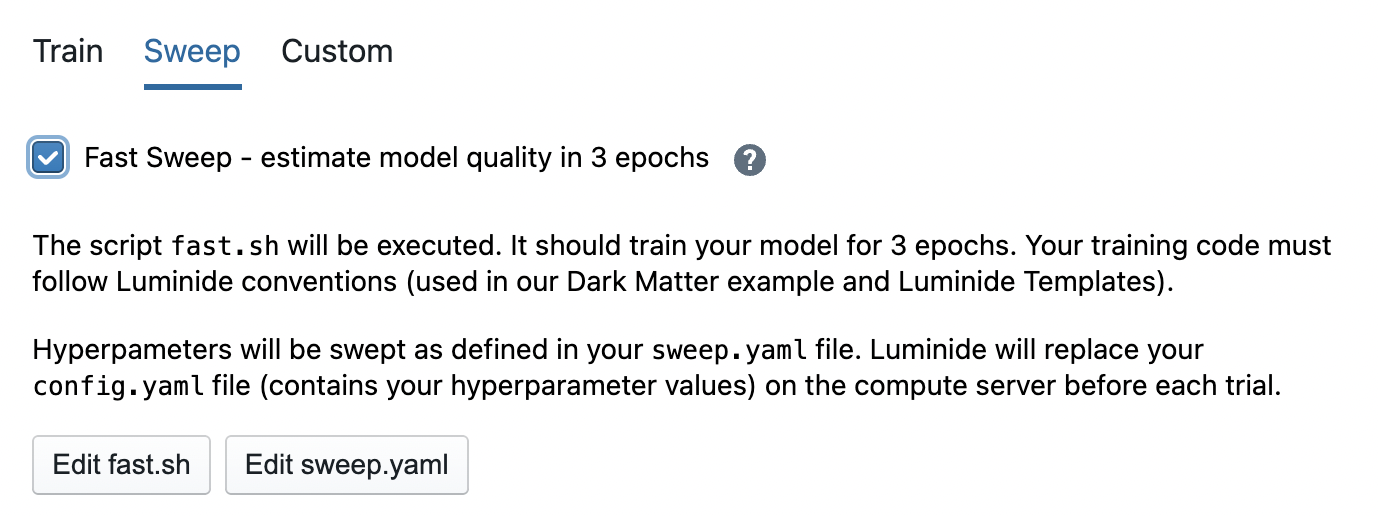
Fast sweeps require more fine-grained training and validation errors to be collected. It is recommended that template-generated code be used to enable this. The expected format for history.csv is:
epoch, iter, train_loss, val_loss
0, 0, 0.5789984, 0.6578998
0, 1, 0.4998457,
…
In this case, “iter” refers to the index of a minibatch within an epoch. The “val_loss” value may be left blank for many minibatches, but should be computed at regular intervals as shown in the train_epoch() function inside train.py.